Redshift Module
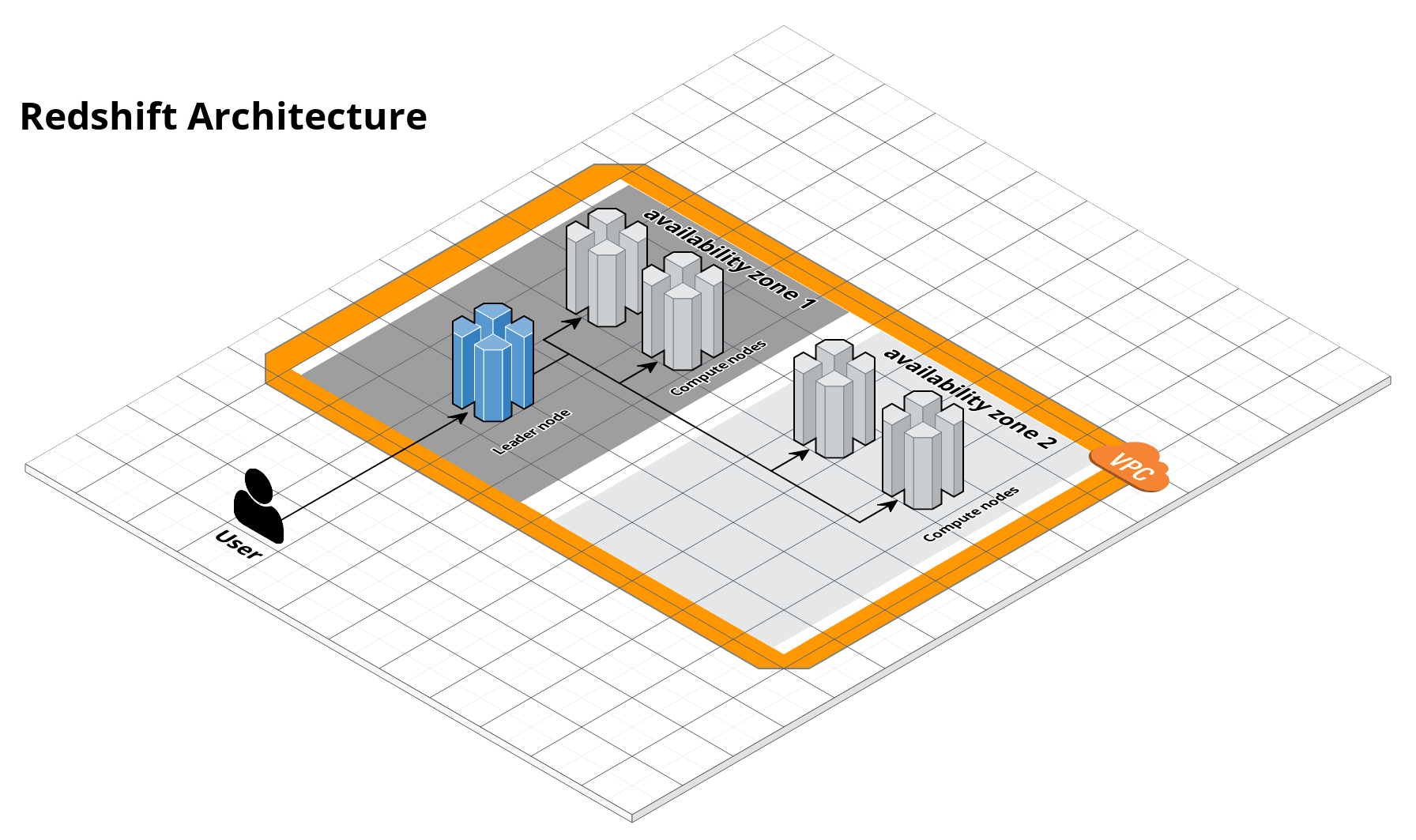
View SourceRelease NotesThis module creates an Amazon Redshift cluster that you can use as a data warehouse. The cluster is managed by AWS and automatically handles leader nodes, worker nodes, backups, patching, and encryption.
 img
img
About Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Refer to the following resources to get more information:
Note: currently, this module does not support Amazon Redshift Serverless.
Serverless
Amazon Redshift Serverless makes it convenient for you to run and scale analytics without having to provision and manage
data warehouses. Use the var.enable_serverless to enable serverless and the var.serverless_base_capacity to set teh
base Redshift Processing Units (RPU) for serving queries.
Refer to the Amazon Redshift Serverless page for more information.
Note: it seems like the terraform destroy command is not working smoothly for Redshift serverless feature
yet (hashicorp/terraform-provider-aws#29962). Users
would likely encounter error when trying to delete a workgroup associated with the Redshift serverless namespace. As a
workaround, you can re-run the destroy command once the workspace gets deleted completely (e.g., after 30 mins).
Sample Usage
- Terraform
- Terragrunt
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S REDSHIFT MODULE
# ------------------------------------------------------------------------------------------------------
module "redshift" {
source = "git::git@github.com:gruntwork-io/terraform-aws-data-storage.git//modules/redshift?ref=v0.29.2"
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# The name used to namespace all resources created by these templates,
# including the DB instance (e.g. drupaldb). Must be unique for this region.
# May contain only lowercase alphanumeric characters, hyphens.
name = <string>
# A list of subnet ids where the database should be deployed. In the standard
# Gruntwork VPC setup, these should be the private persistence subnet ids.
subnet_ids = <list(string)>
# The id of the VPC in which this DB should be deployed.
vpc_id = <string>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of CIDR-formatted IP address ranges that can connect to this DB.
# Should typically be the CIDR blocks of the private app subnet in this VPC
# plus the private subnet in the mgmt VPC. This is ignored if
# create_subnet_group=false.
allow_connections_from_cidr_blocks = []
# A list of Security Groups that can connect to this DB.
allow_connections_from_security_groups = []
# Indicates whether major version upgrades (e.g. 9.4.x to 9.5.x) will ever be
# permitted. Note that these updates must always be manually performed and
# will never automatically applied.
allow_major_version_upgrade = true
# A list of CIDR-formatted IP address ranges that this DB can connect. Use
# this if the database needs to connect to certain IP addresses for special
# operation
allow_outbound_connections_from_cidr_blocks = []
# Indicates that minor engine upgrades will be applied automatically to the DB
# instance during the maintenance window. If set to true, you should set
# var.engine_version to MAJOR.MINOR and omit the .PATCH at the end (e.g., use
# 5.7 and not 5.7.11); otherwise, you'll get Terraform state drift. See
# https://www.terraform.io/docs/providers/aws/r/db_instance.html#engine_version
# for more details.
auto_minor_version_upgrade = true
# The description of the aws_db_security_group that is created. Defaults to
# 'Security group for the var.name DB' if not specified.
aws_db_security_group_description = null
# The name of the aws_db_security_group that is created. Defaults to var.name
# if not specified.
aws_db_security_group_name = null
# How many days to keep backup snapshots around before cleaning them up. Must
# be 1 or greater to support read replicas.
backup_retention_period = 21
# The description of the cluster_subnet_group that is created. Defaults to
# 'Subnet group for the var.name DB' if not specified.
cluster_subnet_group_description = null
# The name of the cluster_subnet_group that is created, or an existing one to
# use if cluster_subnet_group is false. Defaults to var.name if not specified.
cluster_subnet_group_name = null
# If false, the DB will bind to aws_db_subnet_group_name and the CIDR will be
# ignored (allow_connections_from_cidr_blocks)
create_subnet_group = true
# Timeout for DB creating
creating_timeout = "75m"
# A map of custom tags to apply to the RDS Instance and the Security Group
# created for it. The key is the tag name and the value is the tag value.
custom_tags = {}
# The name for your database of up to 8 alpha-numeric characters. If you do
# not provide a name, Amazon RDS will not create a database in the DB cluster
# you are creating.
db_name = "dev"
# Timeout for DB deleting
deleting_timeout = "40m"
# Elastic IP that will be associated with the cluster
elastic_ip = null
# Whether to enable serverless feature or not. Refer to
# https://docs.aws.amazon.com/redshift/latest/gsg/new-user-serverless.html for
# more information.
enable_serverless = false
# If true , enhanced VPC routing is enabled. Forces COPY and UNLOAD traffic
# between the cluster and data repositories to go through your VPC.
enhanced_vpc_routing = false
# The name of the final_snapshot_identifier. Defaults to
# var.name-final-snapshot if not specified.
final_snapshot_name = null
# A list of IAM Role ARNs to associate with the cluster. A Maximum of 10 can
# be associated to the cluster at any time.
iam_roles = null
# The instance type to use for the db (e.g. dc2.large). This field is
# mandatory for provisioned Redshift.
instance_type = null
# The ARN of a KMS key that should be used to encrypt data on disk. Only used
# if var.storage_encrypted is true. If you leave this blank, the default RDS
# KMS key for the account will be used.
kms_key_arn = null
# Configures logging information such as queries and connection attempts for
# the specified Amazon Redshift cluster. If enable is set to true. The
# bucket_name and s3_key_prefix must be set. The bucket must be in the same
# region as the cluster and the cluster must have read bucket and put object
# permission.
logging = {"bucket_name":null,"enable":false,"s3_key_prefix":null}
# The weekly day and time range during which system maintenance can occur
# (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or
# there may even be a downtime during maintenance windows.
maintenance_window = "sun:07:00-sun:08:00"
# The password for the master user. If var.snapshot_identifier is non-empty,
# this value is ignored. Required unless var.replicate_source_db is set.
master_password = null
# The username for the master user. Required unless var.replicate_source_db is
# set.
master_username = null
# The number of nodes in the cluster. This field is mandatory for provisioned
# Redshift.
number_of_nodes = null
# Name of a Redshift parameter group to associate.
parameter_group_name = null
# The port the DB will listen on (e.g. 3306)
port = 5439
# WARNING: - In nearly all cases a database should NOT be publicly accessible.
# Only set this to true if you want the database open to the internet.
publicly_accessible = false
# This setting specifies the base data warehouse capacity Amazon Redshift uses
# to serve queries. Base capacity is specified in RPUs. You can set a base
# capacity in Redshift Processing Units (RPUs). One RPU provides 16 GB of
# memory. You can adjust the Base capacity setting from 8 RPUs to 512 RPUs in
# units of 8. This field is mandatory for serverless.
serverless_base_capacity = null
# Determines whether a final DB snapshot is created before the DB instance is
# deleted. Be very careful setting this to true; if you do, and you delete
# this DB instance, you will not have any backups of the data!
skip_final_snapshot = false
# If non-null, the name of the cluster the source snapshot was created from.
snapshot_cluster_identifier = null
# If non-null, the Redshift cluster will be restored from the given Snapshot
# ID. This is the Snapshot ID you'd find in the Redshift console, e.g:
# rs:production-2015-06-26-06-05.
snapshot_identifier = null
# Required if you are restoring a snapshot you do not own, optional if you own
# the snapshot. The AWS customer account used to create or copy the snapshot.
snapshot_owner_account = null
# Specifies whether the DB instance is encrypted.
storage_encrypted = true
# Timeout for DB updating
updating_timeout = "75m"
}
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S REDSHIFT MODULE
# ------------------------------------------------------------------------------------------------------
terraform {
source = "git::git@github.com:gruntwork-io/terraform-aws-data-storage.git//modules/redshift?ref=v0.29.2"
}
inputs = {
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# The name used to namespace all resources created by these templates,
# including the DB instance (e.g. drupaldb). Must be unique for this region.
# May contain only lowercase alphanumeric characters, hyphens.
name = <string>
# A list of subnet ids where the database should be deployed. In the standard
# Gruntwork VPC setup, these should be the private persistence subnet ids.
subnet_ids = <list(string)>
# The id of the VPC in which this DB should be deployed.
vpc_id = <string>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of CIDR-formatted IP address ranges that can connect to this DB.
# Should typically be the CIDR blocks of the private app subnet in this VPC
# plus the private subnet in the mgmt VPC. This is ignored if
# create_subnet_group=false.
allow_connections_from_cidr_blocks = []
# A list of Security Groups that can connect to this DB.
allow_connections_from_security_groups = []
# Indicates whether major version upgrades (e.g. 9.4.x to 9.5.x) will ever be
# permitted. Note that these updates must always be manually performed and
# will never automatically applied.
allow_major_version_upgrade = true
# A list of CIDR-formatted IP address ranges that this DB can connect. Use
# this if the database needs to connect to certain IP addresses for special
# operation
allow_outbound_connections_from_cidr_blocks = []
# Indicates that minor engine upgrades will be applied automatically to the DB
# instance during the maintenance window. If set to true, you should set
# var.engine_version to MAJOR.MINOR and omit the .PATCH at the end (e.g., use
# 5.7 and not 5.7.11); otherwise, you'll get Terraform state drift. See
# https://www.terraform.io/docs/providers/aws/r/db_instance.html#engine_version
# for more details.
auto_minor_version_upgrade = true
# The description of the aws_db_security_group that is created. Defaults to
# 'Security group for the var.name DB' if not specified.
aws_db_security_group_description = null
# The name of the aws_db_security_group that is created. Defaults to var.name
# if not specified.
aws_db_security_group_name = null
# How many days to keep backup snapshots around before cleaning them up. Must
# be 1 or greater to support read replicas.
backup_retention_period = 21
# The description of the cluster_subnet_group that is created. Defaults to
# 'Subnet group for the var.name DB' if not specified.
cluster_subnet_group_description = null
# The name of the cluster_subnet_group that is created, or an existing one to
# use if cluster_subnet_group is false. Defaults to var.name if not specified.
cluster_subnet_group_name = null
# If false, the DB will bind to aws_db_subnet_group_name and the CIDR will be
# ignored (allow_connections_from_cidr_blocks)
create_subnet_group = true
# Timeout for DB creating
creating_timeout = "75m"
# A map of custom tags to apply to the RDS Instance and the Security Group
# created for it. The key is the tag name and the value is the tag value.
custom_tags = {}
# The name for your database of up to 8 alpha-numeric characters. If you do
# not provide a name, Amazon RDS will not create a database in the DB cluster
# you are creating.
db_name = "dev"
# Timeout for DB deleting
deleting_timeout = "40m"
# Elastic IP that will be associated with the cluster
elastic_ip = null
# Whether to enable serverless feature or not. Refer to
# https://docs.aws.amazon.com/redshift/latest/gsg/new-user-serverless.html for
# more information.
enable_serverless = false
# If true , enhanced VPC routing is enabled. Forces COPY and UNLOAD traffic
# between the cluster and data repositories to go through your VPC.
enhanced_vpc_routing = false
# The name of the final_snapshot_identifier. Defaults to
# var.name-final-snapshot if not specified.
final_snapshot_name = null
# A list of IAM Role ARNs to associate with the cluster. A Maximum of 10 can
# be associated to the cluster at any time.
iam_roles = null
# The instance type to use for the db (e.g. dc2.large). This field is
# mandatory for provisioned Redshift.
instance_type = null
# The ARN of a KMS key that should be used to encrypt data on disk. Only used
# if var.storage_encrypted is true. If you leave this blank, the default RDS
# KMS key for the account will be used.
kms_key_arn = null
# Configures logging information such as queries and connection attempts for
# the specified Amazon Redshift cluster. If enable is set to true. The
# bucket_name and s3_key_prefix must be set. The bucket must be in the same
# region as the cluster and the cluster must have read bucket and put object
# permission.
logging = {"bucket_name":null,"enable":false,"s3_key_prefix":null}
# The weekly day and time range during which system maintenance can occur
# (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or
# there may even be a downtime during maintenance windows.
maintenance_window = "sun:07:00-sun:08:00"
# The password for the master user. If var.snapshot_identifier is non-empty,
# this value is ignored. Required unless var.replicate_source_db is set.
master_password = null
# The username for the master user. Required unless var.replicate_source_db is
# set.
master_username = null
# The number of nodes in the cluster. This field is mandatory for provisioned
# Redshift.
number_of_nodes = null
# Name of a Redshift parameter group to associate.
parameter_group_name = null
# The port the DB will listen on (e.g. 3306)
port = 5439
# WARNING: - In nearly all cases a database should NOT be publicly accessible.
# Only set this to true if you want the database open to the internet.
publicly_accessible = false
# This setting specifies the base data warehouse capacity Amazon Redshift uses
# to serve queries. Base capacity is specified in RPUs. You can set a base
# capacity in Redshift Processing Units (RPUs). One RPU provides 16 GB of
# memory. You can adjust the Base capacity setting from 8 RPUs to 512 RPUs in
# units of 8. This field is mandatory for serverless.
serverless_base_capacity = null
# Determines whether a final DB snapshot is created before the DB instance is
# deleted. Be very careful setting this to true; if you do, and you delete
# this DB instance, you will not have any backups of the data!
skip_final_snapshot = false
# If non-null, the name of the cluster the source snapshot was created from.
snapshot_cluster_identifier = null
# If non-null, the Redshift cluster will be restored from the given Snapshot
# ID. This is the Snapshot ID you'd find in the Redshift console, e.g:
# rs:production-2015-06-26-06-05.
snapshot_identifier = null
# Required if you are restoring a snapshot you do not own, optional if you own
# the snapshot. The AWS customer account used to create or copy the snapshot.
snapshot_owner_account = null
# Specifies whether the DB instance is encrypted.
storage_encrypted = true
# Timeout for DB updating
updating_timeout = "75m"
}
Reference
- Inputs
- Outputs
Required
namestringThe name used to namespace all resources created by these templates, including the DB instance (e.g. drupaldb). Must be unique for this region. May contain only lowercase alphanumeric characters, hyphens.
subnet_idslist(string)A list of subnet ids where the database should be deployed. In the standard Gruntwork VPC setup, these should be the private persistence subnet ids.
vpc_idstringThe id of the VPC in which this DB should be deployed.
Optional
allow_connections_from_cidr_blockslist(string)A list of CIDR-formatted IP address ranges that can connect to this DB. Should typically be the CIDR blocks of the private app subnet in this VPC plus the private subnet in the mgmt VPC. This is ignored if create_subnet_group=false.
[]allow_connections_from_security_groupslist(string)A list of Security Groups that can connect to this DB.
[]Indicates whether major version upgrades (e.g. 9.4.x to 9.5.x) will ever be permitted. Note that these updates must always be manually performed and will never automatically applied.
trueallow_outbound_connections_from_cidr_blockslist(string)A list of CIDR-formatted IP address ranges that this DB can connect. Use this if the database needs to connect to certain IP addresses for special operation
[]Indicates that minor engine upgrades will be applied automatically to the DB instance during the maintenance window. If set to true, you should set engine_version to MAJOR.MINOR and omit the .PATCH at the end (e.g., use 5.7 and not 5.7.11); otherwise, you'll get Terraform state drift. See https://www.terraform.io/docs/providers/aws/r/db_instance.html#engine_version for more details.
trueThe description of the aws_db_security_group that is created. Defaults to 'Security group for the name DB' if not specified.
nullThe name of the aws_db_security_group that is created. Defaults to name if not specified.
nullbackup_retention_periodnumberHow many days to keep backup snapshots around before cleaning them up. Must be 1 or greater to support read replicas.
21The description of the cluster_subnet_group that is created. Defaults to 'Subnet group for the name DB' if not specified.
nullThe name of the cluster_subnet_group that is created, or an existing one to use if cluster_subnet_group is false. Defaults to name if not specified.
nullIf false, the DB will bind to aws_db_subnet_group_name and the CIDR will be ignored (allow_connections_from_cidr_blocks)
truecreating_timeoutstringTimeout for DB creating
"75m"custom_tagsmap(string)A map of custom tags to apply to the RDS Instance and the Security Group created for it. The key is the tag name and the value is the tag value.
{}db_namestringThe name for your database of up to 8 alpha-numeric characters. If you do not provide a name, Amazon RDS will not create a database in the DB cluster you are creating.
"dev"deleting_timeoutstringTimeout for DB deleting
"40m"elastic_ipstringElastic IP that will be associated with the cluster
nullWhether to enable serverless feature or not. Refer to https://docs.aws.amazon.com/redshift/latest/gsg/new-user-serverless.html for more information.
falseIf true , enhanced VPC routing is enabled. Forces COPY and UNLOAD traffic between the cluster and data repositories to go through your VPC.
falsefinal_snapshot_namestringThe name of the final_snapshot_identifier. Defaults to name-final-snapshot if not specified.
nulliam_roleslist(string)A list of IAM Role ARNs to associate with the cluster. A Maximum of 10 can be associated to the cluster at any time.
nullinstance_typestringThe instance type to use for the db (e.g. dc2.large). This field is mandatory for provisioned Redshift.
nullkms_key_arnstringThe ARN of a KMS key that should be used to encrypt data on disk. Only used if storage_encrypted is true. If you leave this blank, the default RDS KMS key for the account will be used.
nullloggingobject(…)Configures logging information such as queries and connection attempts for the specified Amazon Redshift cluster. If enable is set to true. The bucket_name and s3_key_prefix must be set. The bucket must be in the same region as the cluster and the cluster must have read bucket and put object permission.
object({
enable = bool
bucket_name = string
s3_key_prefix = string
})
{
bucket_name = null,
enable = false,
s3_key_prefix = null
}
maintenance_windowstringThe weekly day and time range during which system maintenance can occur (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or there may even be a downtime during maintenance windows.
"sun:07:00-sun:08:00"master_passwordstringThe password for the master user. If snapshot_identifier is non-empty, this value is ignored. Required unless replicate_source_db is set.
nullmaster_usernamestringThe username for the master user. Required unless replicate_source_db is set.
nullnumber_of_nodesnumberThe number of nodes in the cluster. This field is mandatory for provisioned Redshift.
nullparameter_group_namestringName of a Redshift parameter group to associate.
nullportnumberThe port the DB will listen on (e.g. 3306)
5439WARNING: - In nearly all cases a database should NOT be publicly accessible. Only set this to true if you want the database open to the internet.
falseserverless_base_capacitynumberThis setting specifies the base data warehouse capacity Amazon Redshift uses to serve queries. Base capacity is specified in RPUs. You can set a base capacity in Redshift Processing Units (RPUs). One RPU provides 16 GB of memory. You can adjust the Base capacity setting from 8 RPUs to 512 RPUs in units of 8. This field is mandatory for serverless.
nullDetermines whether a final DB snapshot is created before the DB instance is deleted. Be very careful setting this to true; if you do, and you delete this DB instance, you will not have any backups of the data!
falseIf non-null, the name of the cluster the source snapshot was created from.
nullsnapshot_identifierstringIf non-null, the Redshift cluster will be restored from the given Snapshot ID. This is the Snapshot ID you'd find in the Redshift console, e.g: rs:production-2015-06-26-06-05.
nullsnapshot_owner_accountstringRequired if you are restoring a snapshot you do not own, optional if you own the snapshot. The AWS customer account used to create or copy the snapshot.
nullSpecifies whether the DB instance is encrypted.
trueupdating_timeoutstringTimeout for DB updating
"75m"Amazon Resource Name (ARN) of cluster
The name of the Database in the cluster
The DNS name of the cluster
The cluter's connection endpoint
The Redshift Cluster ID
The name of the Redshift cluster
The name of the parameter group associated with this cluster
The Port the cluster responds on
The ID of the Security Group that controls access to the cluster